
此篇博文只有核心理论概念(只有定义,基本操作实现见仓库),具体代码见我的 GitHub 仓库,Data Structures For C Language。/ 参考了若干本书,都不尽相同,加上书中发现了不少错误,所以以我自己写出的实际能运行的代码为准(综合了若干本书中的内容)。
参考:
1、 《数据结构考研复习指导》
2、 《大话数据结构》
3、 《数据结构算法解析》 高一凡
4、 《数据结构》 清华大学出版社
一 绪论
1 知识框架
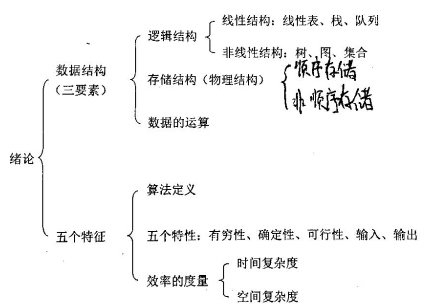
2 数据结构基本概念
- 概念与术语:
- 数据:信息的载体,对客观世界的描述,计算机程序可识别处理的符号集合。
- 数据元素:数据的基本单位。数据元素由数据项组成,数据项是构成数据元素的最小单位(数据项 -> 数据元素 -> 数据)。
- 数据对象:数据的一个子集。相同性质的数据元素的集合(多个同性质的数据元素)。
- 数据类型:一个值的集合及其操作。原子类型(值不可再分)、结构类型(值可再分)、抽象数据类型(抽象数据组织与操作)。
- 抽象数据类型(ADT):数学模型及其操作。是逻辑特性。由数据对象、数据关系、基本操作集组成。
- 数据结构:数据元素间的关系。数据结构包括三方面,逻辑结构、存储结构、数据的运算。
数据结构的三要素:
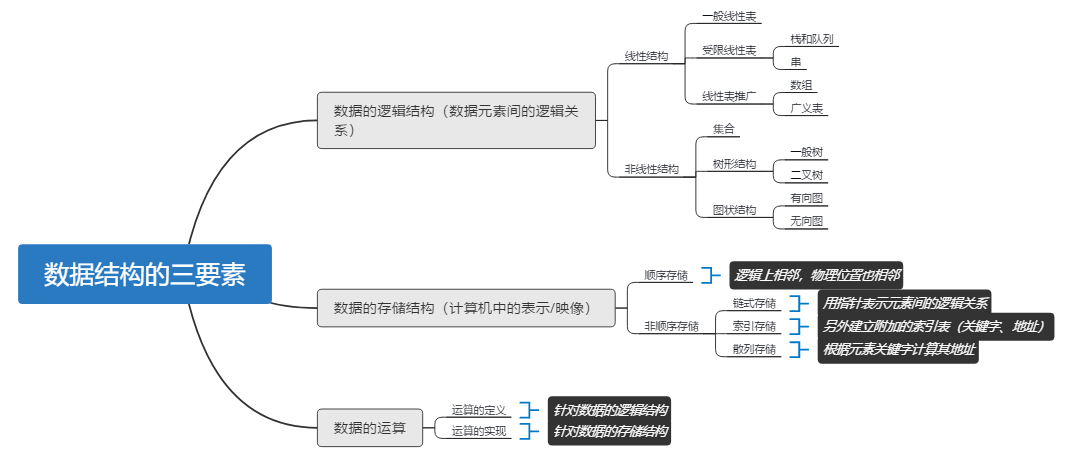
数据的几种存储结构优劣:
- 顺序存储:优点是可随机存取,每个数据元素占用最少存储空间;缺点是只能使用一整块存储单元,产生外部碎片。
- 链式存储:优点是不会出现碎片,充分利用存储单元;缺点是存储指针占用额外空间,只能顺序存取。
- 索引存储:优点是检索速度快;缺点是索引表占用额外空间,修改数据时对索引表修改花费更多时间。
- 散列存储:优点是检索、修改快;缺点是元素存储单元可能冲突,处理冲突增加时空开销。
- 补充:
- 逻辑结构与存储结构的关系:逻辑结构是对数据结构的抽象,存储结构是对数据结构的实现。
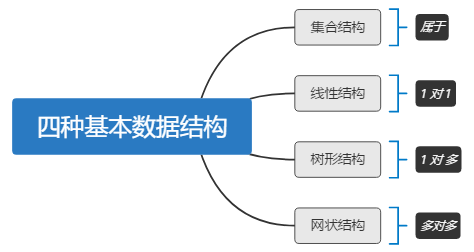
- 四种基本数据结构:
- 数据结构、表格、关系数据库基本概念对比:数据项、数据元素、数据对象。/ 字段、记录、表。/ 属性、元组、关系。
3 算法和算法评价
- 算法的基本概念:
- 定义:算法是对特定问题求解步骤的一种描述,是指令的有限序列。
- 特征:有穷性、确定性、可行性、输入、输出。
- 算法的效率度量(时间复杂度 T(n)):
概念:
T(n)=O(f(n))。用算法中基本运算(最深层循环内的语句)的频度 f(n) 来衡量算法的时间复杂度。算法中所有语句频度之和为 T(n),T(n)=O(f(n)),O 在数学上为同数量级的意思,n 为问题的规模。即问题规模越大,基本运算的频度越大(所有语句频度之和越大)。影响因素:
一是问题规模 n;二是待输入数据的性质(如输入数据元素的初始状态)。/ 最坏(通常用此来衡量)、平均、最好时间复杂度。计算方法:
加法法则(取最大的基本运算频度):T(n)=T1(n)+T2(n)=O(f(n))+O(g(n))=O(max(f(n),g(n)));
乘法法则(若干基本运算频度相乘):T(n)=T1(n)xT2(n)=O(f(n))xO(g(n))=O(f(n)xg(n))。常见渐进时间复杂度:
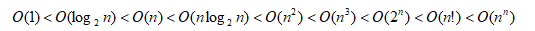
- 算法的效率度量(空间复杂度 S(n)):
- 概念:
S(n)=O(g(n))。该算法所消耗的存储空间(对数据操作,实现计算所需要的辅助空间;输入数据所需空间与算法无关时,除去输入、程序占的空间外,额外所需要的空间)。
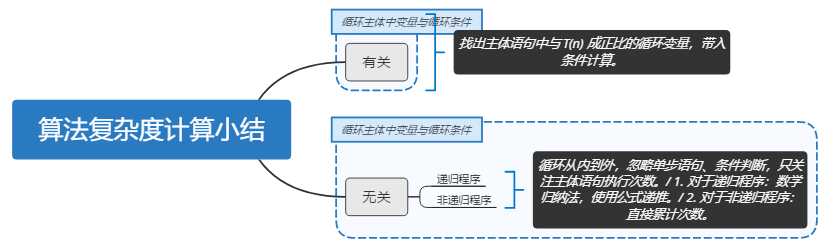
- 算法复杂度计算小结(分析时间复杂度):
- 有关:根据循环中的变量计算循环中变量最终的值,将这个计算值的表达式代入条件中的变量。

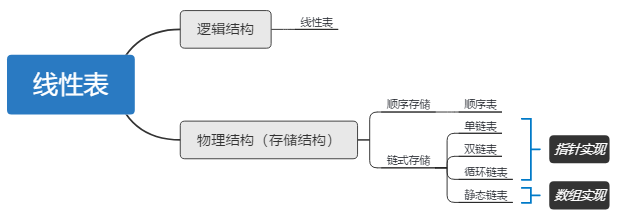
二 线性表
1 知识框架
2 线性表的定义、基本操作
线性表的定义:
线性表 L(名字),由具有 n>=0 个相同数据类型的数据元素组成的有限序列。线性表的特点:
- 元素个数是有限个。
- 在序列中,各个元素排序有先后次序。
- 每个元素都是单个元素,数据类型都相同。
- 表中元素只讨论逻辑关系。
- 线性表的基本操作:
最核心最基本的操作,其它操作可由其调用而来。(下面括号里的是实参,非形参)。
- InitList(&L):初始化一个空的线性表。
- DestroyList(&L):销毁操作。
- ListInsert(&L, i, e):按位置插入操作。
- ListDelete(&L, i, &e):删除某位置操作。
- LocateElem(L, e):按值查找。
- GetElem(L, i, &e):按位置查找。
- Length(L):求表长,即元素个数。
- Empty(L):判空操作。
- PrintList(L):输出 L 操作。
3 线性表的顺序表示(SqList、SeqList)
- 顺序表的定义、特点:
- 定义:线性表的顺序存储即顺序表。用一组地址连续的存储单元,依次存储线性表中的数据元素。逻辑上相邻的两个元素,在物理上也相邻。
- 特点:适用于数据相对稳定的线性表。可随机访问,存储密度高,插入删除操作需移动大量元素。
1 | // 静态分配的一维数组实现。 |
- 顺序表的基本操作:
顺序表的基本操作 GitHub 代码
1 | // 初始化一个空的线性表 |
4 线性表的链式表示
(1)单链表 LNode
- 单链表的定义、特点:
- 定义:每个链表节点,由数据域、指针域组成。数据域存放数据元素,指针域存放后继节点的地址。/ 用单独的一个头节点来标识一个单链表。头节点中指针域为 NULL 表示空表,头节点数据域可以不存任何放东西,也可以存放表长等信息。(先创建一个单链表指针变量,然后将一个头节点地址赋给它。)/ 我的实现是先创建单链表(头节点),然后创建一个节点并将此节点插入。而书上是在创建时就创建若干个节点并插入。
- 特点:不需要像顺序表一样要大量连续的存储空间。但指针域需要额外的存储空间。需要从表头遍历一次查找,非随机访问。
1 | // 单链表(头节点也用此结构) |
- 单链表的基本操作:
单链表的基本操作 GitHub 代码
注意,我自己写的代码和书上的不同,但是本质原理是一样的。
1 | // 单链表的头节点创建(创建一个头节点,将头节点地址赋给单链表指针变量) |
(2)双链表 DNode
- 双链表的定义、特点:
(3)循环链表
- 循环链表的定义、特点:
(4)静态链表 SlinkList
- 静态链表的定义、特点:
