
参考:
1、 爬虫打破封禁的六种方法
2、 接口访问频次权限
3、 friendships/friends/bilateral
4、 微博 SDK
一 想法
此处参考我的另一篇博文:《爬虫:微博好友关系分析》
通过微博抓取微博好友,然后抓取好友的好友,以自己到直接好友为一度人脉,依次类推。/ 社交关系网络的构成是节点和边,人物就是节点,边(连线)即是关系。即为 source、target。
分析问题复杂度,为简单,化简为只抓取互相关注的(微博客户端用户粉丝里可直接看到相互关注的),这也符合常理,通常相互关注的更可能是好友关系。假设每个人互关的好友数是常数 a = 20 人,那么一共要抓取的人数(总数关系的数据量)y 是人脉度数 x 的幂函数。一度人脉一个乘号,假设 2 度人脉,每个人互关好友 20 人,即 y = 20 x 20 = 400。这个数据量还可以接受。所以决定抓取二度人脉进行分析。考虑到二度人脉做可视化分析、爬取难度等方面比较合适。
步骤:
先抓取用户信息,然后对原始数据进行分析。问题细化:
- 怎样模拟登陆微博,要不要考虑 IP 地址被禁问题
- 怎样抓取到数据
- 需要抓那些数据
- 数据存放在哪、怎样存放
- 怎样对数据清洗筛选
- 用什么工具、怎样分析数据得出有价值的结论
二 为什么通过手机客户端
爬虫的核心问题就是抓取自己想要的数据。但是有两个问题,怎样抓到想要的数据?爬虫程序会不会被反爬机制限制?显然后者更重要,如果被限制就根本无法抓取数据了。
通过查阅资料,通常的技巧是抓取手机网页版的,而不是 pc 网页版,因为前者反爬机制通常更弱,这算是一个小技巧。
但是手机网页版的数据太少,那么要不要考虑一下手机客户端呢,于是有了此篇博文。
三 先上结论
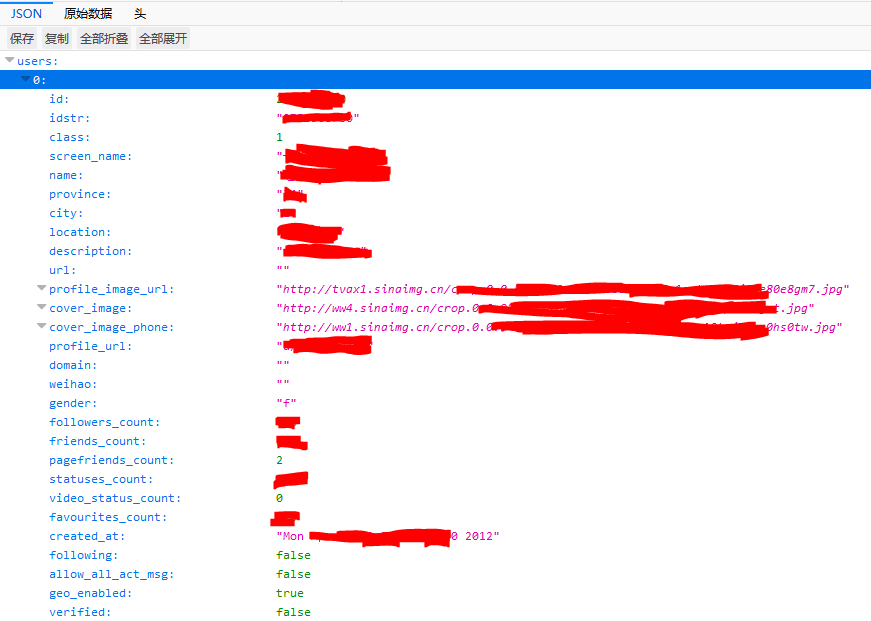
抓取一个用户的互关好友及其详细信息,可以直接通过此用户 uid 构造 URL 来获得一个 json 文件,此 json 文件包含了所有互关好友的详细信息。
假设每个人 20 个互关好友,一个人的二度人脉总数是 400 人。通过获取一个用户互关好友 json 的方法,只需要一共请求 21 次(一度人脉 + 二度人脉)即可!然后分析 json 文件即可得到约 400 人信息(假设不重复)。
通过导出的 URL 放到 PC 浏览器中,可以看到 json 文件的请求头,可以根据 json 文件构造爬虫代码。
四 具体分析过程
使用 iPhone 微博国际版。
使用一个买来的小号登录。
搜索想要研究的对象(如自己)。
停留在研究对象的主页。
开始使用手机上的 Thor 抓包,记录下互相关注的一度人脉(点击粉丝 -> 点击互相关注全部 -> 停止抓包)。分析获取到 json 的数据包。完成一度人脉获取的方法。
返回到研究对象的一度人脉列表,点击第一个好友,点击粉丝 -> 点击互相关注全部 -> 停止抓包。再重复此动作两次。获得三个获取二度人脉的数据包样本。
分析抓到的数据包,发现其中两个数据包就是请求的某个用户的互关好友信息(json 文件)。/ 通过对比发现这两个区别在于导出的 URL 中只有 count 参数不同,一个是 50,一个是 10,前者的 json 文件也大些。参数为 10 的只有 10 个互关好友的信息。因此用参数 50。推测最多能获取到一个人互关的 50 个好友信息。查看微博开发文档发现默认为 50,上限 500,返回 30% 的互关好友。必须要授权才能访问,friendships/friends/bilateral。

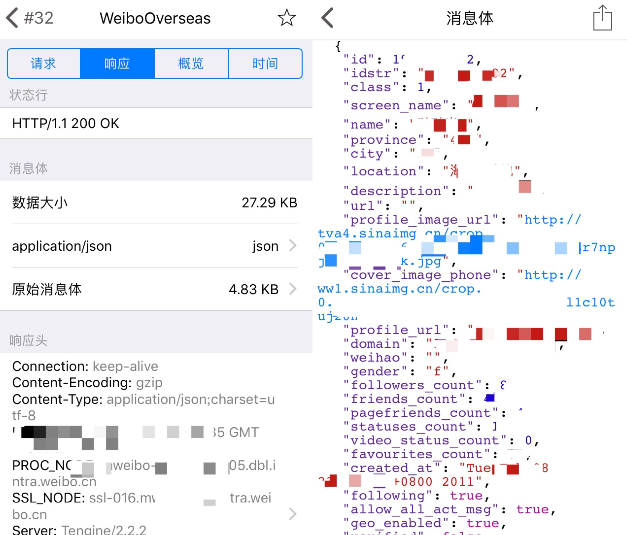
分析这些可以获得信息的有效数据包,找出共同规律。(第一个为一度人脉互关好友,剩下依次为互关好友中第一个好友的互关好友信息,互关好友中第二个…)
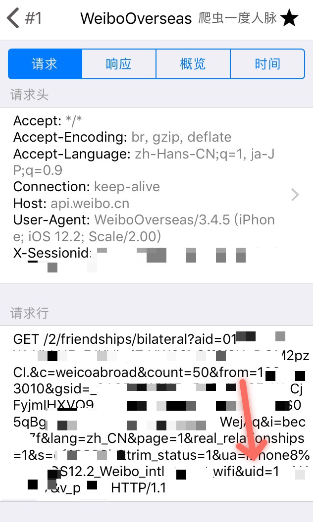
通过分析客户端数据包,发现可以通过构造 URI 来直接获得某个用户互关好友的 json 文件。uid 就是指定的用户,其他参数可以构造出来。(这里需要构造的参数就是微博小号在分析过程中抓到的可以获取 json 的 URL 除去 uid 部分。(可以直接使用,爬虫程序中 uid 作为变量即可。)/ 在 Thor 软件中导出原始连接,可以直接在浏览器中打开。
五 获取数据的 URL
- 其 URL 构成:
想要获得数据,必须要构造出 URL,URL 中有几个参数不确定,任务是想办法获取到参数值。/ 用两台不同的手机不同账号下抓包对比。
https://api.weibo.cn/2/friendships/bilateral?aid=XXX.&c=weicoabroad&count=50&from=XXX&gsid=XXX&i=XXX&lang=zh_CN&page=1&real_relationships=1&s=XXX&trim_status=1&ua=iPhone6%2C1_iOS12.2_Weibo_intl._3450_wifi&uid=用户&v_p=XXX
- 重要的 URL 参数:
- aid
- gsid
- i
- s
- uid(指定用户的 uid)
通过观察发现,只需要获得四个参数值即可。参数值要么是客户端生成的,要么是服务器生成的,所以从登陆客户端开始抓包试试。删掉客户端重新下载,从打开开始抓包。
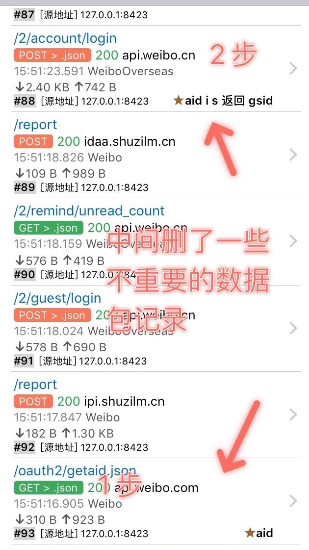
通过分析手机客户端登录过程,发现两个重要的数据包。一个是通过加盐等方法请求授权的,另一个是通过某种方法得到的参数 aid、i、s 等参数构造请求,然后返回一个 gsid。/ 但是没弄清是怎样得到这些参数的,所以想通过模拟客户端登陆来获得参数,然后构造出 URL 的想法宣告失败。
六 总结
虽然想通过模拟客户端登陆来获得参数,然后构造出 URL 的想法宣告失败。但可以曲线救国,直接通过抓包获得 URL,在 Python 爬虫代码中直接使用这个 URL 即可,不用去自己构造,但是爬虫的功能减弱,意味着使用此爬虫的人需要自己用手机客户端抓包去获得这个 URL,然后配置在代码里。/ 之所以用客户端方式,不去模拟网页登陆是因为,客户端可以直接获得互关好友,而网页需要抓取关注和粉丝数据然后自己取交集计算。
爬虫分析人际关系的两种思路:a)直接客户端抓包获取可以得到互关好友信息的 json 文件,然后数据分析。请求数在几十个,非常少。 b)通过网页方法,抓取关注和粉丝进行分析。请求数很多,必须要考虑反爬问题。
